-
 Circular Buffers, Part Two!
Circular Buffers, Part Two!
- Date Mon 21 March 2016
- By Jason Jones
- Category article
- Tags article buffer c
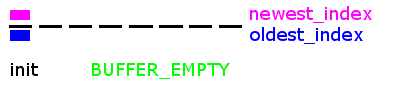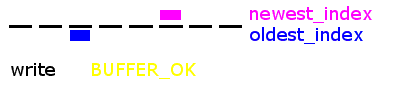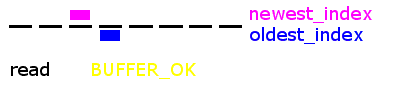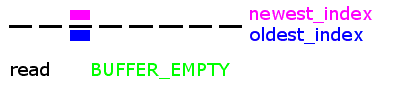
For some background, go back to read the previous post on circular buffers.
Mistakes were made
So, I was implementing a circular buffer on a different project and - lo and behold - I have made a mistake in the implementation of the circular buffer! We last visited the circular buffer in a post a few weeks ago. The implementation in github at that time was fully functional, but it did not use all of the slots available as was advertised by the last entry. The next version of code has corrected this mistake.
The Problem
The root of the problem is demonstrated by the graphic above. The last implementation was 'stateless', meaning that it didn't keep track of the state of the circular buffer. There are two states - BUFFER_EMPTY and BUFFER_FULL - which look exactly the same on the linear array on which the circular array is constructed!
The Solution
We simply added a state to the circular buffer. If the code is reading the buffer and the indexes become equal, then the new buffer state is 'empty'. If you were writing to the buffer and the indexes become equal, then the new buffer state is 'full'. Easy enough.
Empty Slots vs. Full Slots
The library into which I was implementing the circular buffer also had an additional requirement of knowing how many slots were 'readable' and how many slots were writeable. We added the functions BUF_emptySlots() and BUF_fullSlots() so that we could easily extract this information from the buffer.
Finally, the BUF_read() function was a bit clunky to use since it required the creation of an element, then the pass-by-reference, and so on. I found it much easier to understand the BUF_read() function when it simply returned the next value in the series rather than the buffer status. There is a function that returns the buffer status if the application requires it, so there is little need for the read function to return the status.
- article
- current-sensor
- curve-tracer
- dispatch
- fan-controller
- fixed-point-math
- load-cell-sensor
- meta
- reference


 RSS
RSS
2
assembly
5
buffer
31
c
3
current sensor
28
curve tracer
2
fan controller
6
fixed-point math
4
interrupt
3
KiCAD
3
labview
5
layout
6
msp430
4
pelican
18
pic24
29
project
12
python
2
Q1.15
4
schematic
10
serial
3
solidworks
2
task manager
2
theme
3
tkinter
9
uart
9
xc16